
Universities are awash with data about students that could function as early warning signs that a student may need help. These data sources range from the highly personal, for example tutors observing that a student appears to be having a bad day, to the highly systematised, for example automatic early warnings based on a metric such as low attendance or a failed assignment. This piece highlights the three systematic approaches used by learning analytics systems to identify students at risk.
Systematic approaches to identifying students at risk
For this piece, I’m going to focus only on data sources that can be generated systematically, I’m going to ignore sources such as tutor observations of student behaviour. Data derived from tutor/ student relationships is of course crucial, but I’m going to focus on systematic appriaches to early warning. There are broadly three inter-related sources of data:
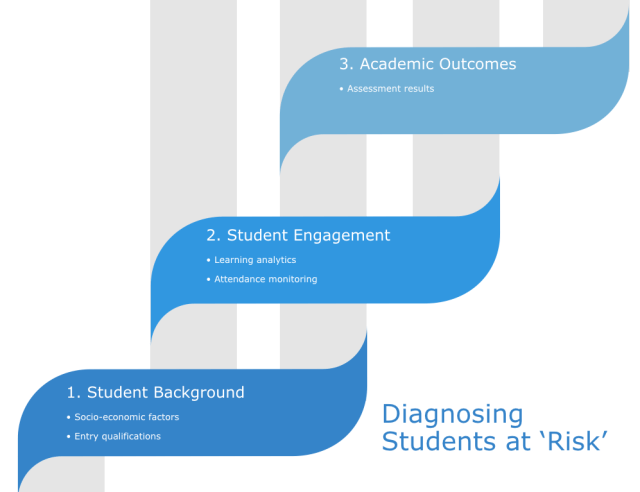
- Student Background
- Student Engagement
- Academic Outcomes
I believe that the evidence shows that the three are strongly connected. For example, our own work shows that students from poorer socio-economic backgrounds have a different pattern of engagement to their more affluent peers and are less likely to achieve the highest academic grades.
1. Student Background
There are perhaps two data sources available here. Firstly there is a student’s socioeconomic background: class, ethnicity, gender, disability status, age etc. Secondly, their entry qualifications: academic/ vocational, grades achieved etc.
These background characteristics can successfully indicate risk of non-progression. There are after all genuine attainment gaps in all HE systems that I’m aware of between students from the wealthiest backgrounds compared to the poorest. However, I’d argue that there’s a risk that this approach stereoptypes students. There are also real challenges for anyone designing interventions: would you be comfortable writing to all BME students advising them that they need additional study support sessions because statistically they are more at risk of withdrawing early?
2. Student Engagement
I’ll use the definition from the earlier entry on student engagement. Student engagement is meaningful time spent engaged in activities associated with passing the course (reading, using the VLE, attending classes, writing assignments etc.). Traditionally attendance has been the main way that engagement has been measured, but in the last 10 years we have seen the rise of more sophisticated learning analytics approaches based on a basket of metrics.
I think that it’s clear by now that there’s a strong correlation between engagement measured in learning analytics systems and student success and potentially this approach can provide very personalised information. The are however drawbacks to this approach – even if the software is relatively cheap, maintaining accurate institutional data probably isn’t.
3. Academic Outcomes
Academic outcomes are chronologically the last of the three data sources to arise. They are only available when students have submitted coursework and had it graded. They are also the most definitive data source, unlike background and engagement that only show likelihood of progressing or not, academic outcomes are very definite with strong institutional rules about passing the year, retakes etc. A student may come from the most disadvantaged background and have very low engagement with the course but still progress, but the most affluent/ advantaged and hardworking student who fails every assignment will not be able to progress.
The main disadvantage with this data source is it’s timeliness. Whilst it might be very definite, if the course is assessed by end of semester examinations, there are real problems with the actionability of this data source. I feel that one of the next important developments in learning analytics may be in improving the link between diagnostic and formative assessments.
As a sidenote, I’m judging that non-submission of assignments is ‘student engagement’, not an ‘academic outcome’ as it relates to learning behaviours, not learning outcomes.
Using these data sources
In the UK, the 2018/19 Social Mobility Commission State of the Nation report found that young people’s life chances remain largely fixed by their social background. This would suggest that we ought to use socio-economic background in learning analytics and many learning analytics systems use a combination of student background and student engagmeent data. I’ve argued previously (accuracy and ethics) that this is ethically uncomfortable and difficult to act upon.
Student background influences their educational outcomes at every level including university. Students don’t leave early because they are from a particular background, they leave early because of a combination of many complex factors that continue to impact upon the way that they engage with their studies. These can (1) include the following:
- motivation/ confidence (including imposter syndrome)
- less well developed learning skills (due to earlier gaps in education/ familial expectations)
- Economic barriers – leading to immediate crises/ need for part-time work etc
Student background influences engagement whilst at University. I remain of the view that targeting behaviour not background is the most important goal. If a student has low engagement because of the barriers above, then they need support because their engagement is low, not because of their background.
(1) The most important word in the sentence is ‘can’. I’m not intending to blame or stereotype.
